爬虫图解:轮子哥关注了哪些人
Table of Contents

前言
本文以知乎大V轮子哥关注的用户列表作为爬虫对象,爬取每个用户的 url_token、昵称、性别、该用户关注其他用户的数量、回答数、文章数、一句话介绍和头像的链接。并将这些数据持久化存储在数据库中,将用户头像下载到本地。最后简单使用 Python 中的 matplotlib 库将爬取的部分信息可视化。
爬虫思路
打开轮子哥知乎上关注的用户列表 ,调出 Chrome 的开发者工具(Developer Tools),重新刷新页面,选择 XHR,第一个就是我们需要的请求信息:
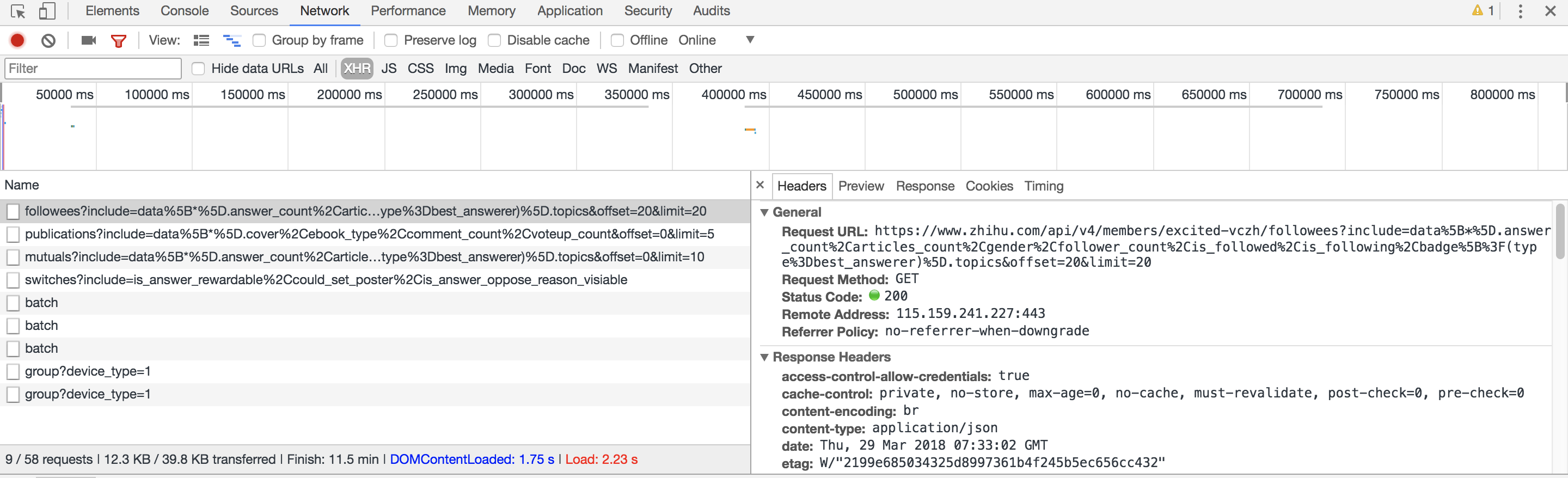
我们观察 请求头 Headers,得知实际该页面的数据请求 URL 为:
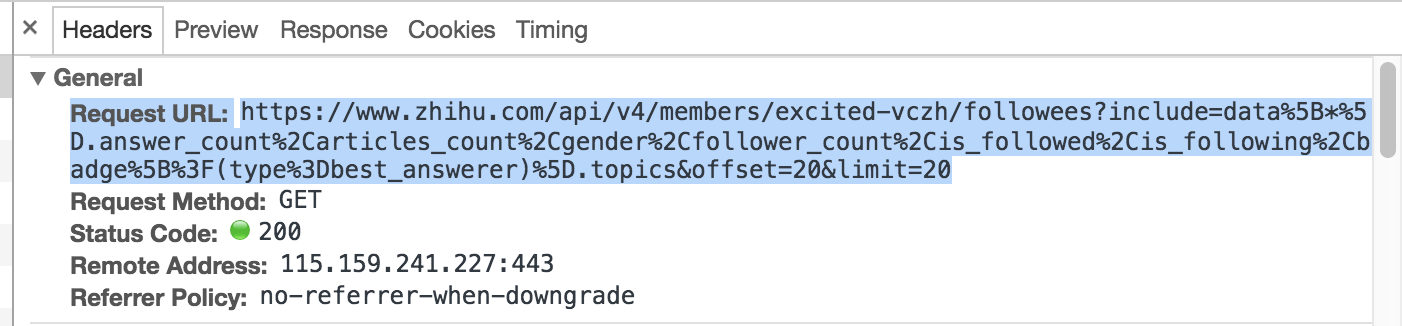
分析这个 URL 的字段,其中 excited-vczh 为轮子哥的 url_token,是知乎识别唯一用户的字段,followees 代表是轮子哥的关注列表,如果是 followers,代表轮子哥的粉丝列表,不难发现 URL 中间部分包含 data、answer_count、articles_count、gender、follower_count 等字段信息,而这些信息正是我们想要的。再看最后的两个字段是 offset,代表用户列表页起始数量,limit 代表每页返回用户信息的数量。
点击 Preview,可以看到格式化后响应的 JSON 数据,源数据可以在 Response 查看。
查看 JSON 数据结构:

根据字段见名知意,其中 avatar_url 就是用户头像链接,avatar_url_template 是头像的路由模板,在该链接中有个 {size} 参数,当我们点击查看网页源码发现,size 为 xll 表示头像大图,所以在程序中,我们每爬到这个链接都需要把 {size} 参数替换成 xll,这样就可以爬取用户较为清楚的头像,这个 JSON 中还有个 badge 字段,表示该用户所获得的徽章,也就是在知乎的成就,比如各个领域的高质量答主,但不是本次爬虫所关心的。每一次请求,都是 20 条用户数据:
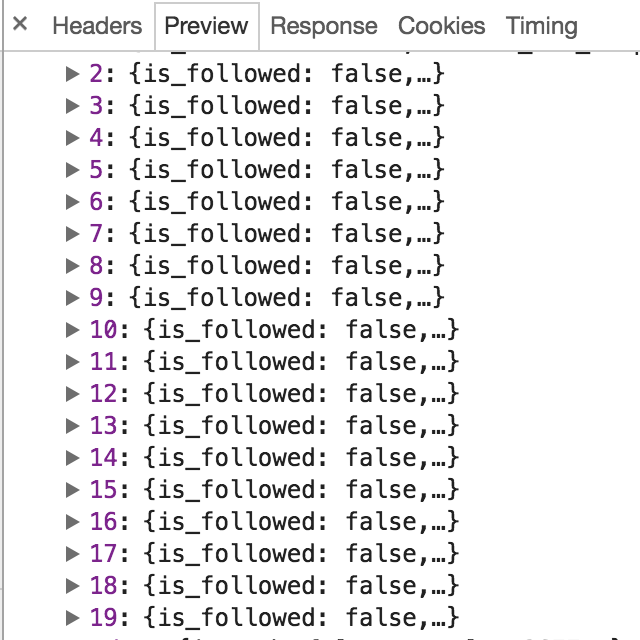
那么问题来了,这时我们确实能够爬虫这 20 个被轮子哥关注的用户的一些数据,但是轮子哥关注的用户肯定不止 20 个,那么其他用户的数据该怎么爬?继续观察 JSON 数据:

有个 paging 字段,该字段下封装了 is_end、totals、previous、is_start、next 五个参数,分别代表:
-
是否是轮子哥关注用户列表的最后一页 URL
-
轮子哥一共关注了多少人
-
当前关注用户列表页的前一页的 URL
-
是否是轮子哥关注用户列表的第一页 URL
-
当前关注用户列表页的下一页的 URL
我们找到轮子哥关注列表的第一页开始爬虫,只需要每页爬虫 20 个用户数据,就获得 next 的值,即下一页 URL,可以继续爬虫,直至所有轮子哥关注的用户全部爬取完成。
实现方法
在网页浏览时,我们可以不用登录知乎帐号就可以查看知乎某个用户关注了哪些人,当我们在没有登录知乎的时候,把上述真正的用户列表 URL 在地址栏访问时,其实是查看不了的:

会显示 error,错误原因是无效授权请求,即对真正的 URL 访问是需要登录的,这样做是避免爬虫,增加爬虫的小障碍,所以程序中要模拟登录,需要模拟成浏览器,避免别服务端发现我们是爬虫把我们拒之门外。验证一下,当我们在网页中登录进知乎,再次输入这个真正的 URL 链接:

说明登录进知乎,我们得到我们想要的数据,这些数据和之前在 Chrome 开发者模式 Preview 中的格式化的数据是一模一样的。
这是非常小规模的爬虫,纯粹使用 urllib 库足以完成需求,对于模拟登录,可以查找登录的实际请求 URL ,根据规则用键值对的形式封装帐号、密码形成 post 请求的数据。另一种是直接是在浏览器中登录后,把整个 cookie 放进程序的请求头中,当然,为了更加逼真体现我们是合法的请求,把 user-agent、accept、accept-language 等信息也放进请求中。在爬虫的同时,也将轮子哥关注的用户的信息进行 MySQL 数据库本地持久化,以便后续的数据可视化,同时也将轮子哥关注的用户的头像存在本地。
结果
- 数据持久化
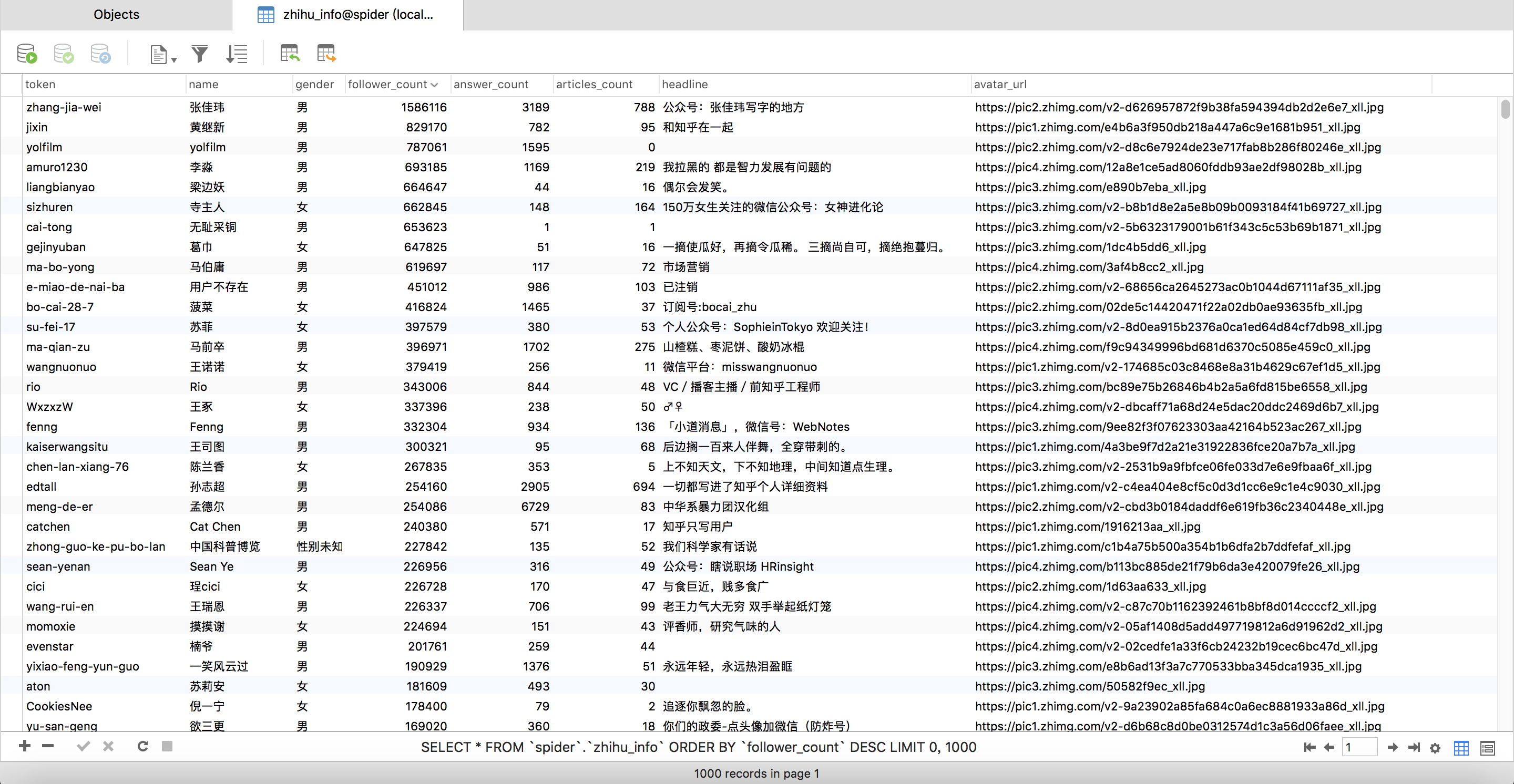
- 头像爬取
- 数据可视化

轮子哥带逛闻名遐迩,今日一见,名不虚传。轮子哥关注的用户中接近三分之二是女性用户,接近三分之一是男性用户。
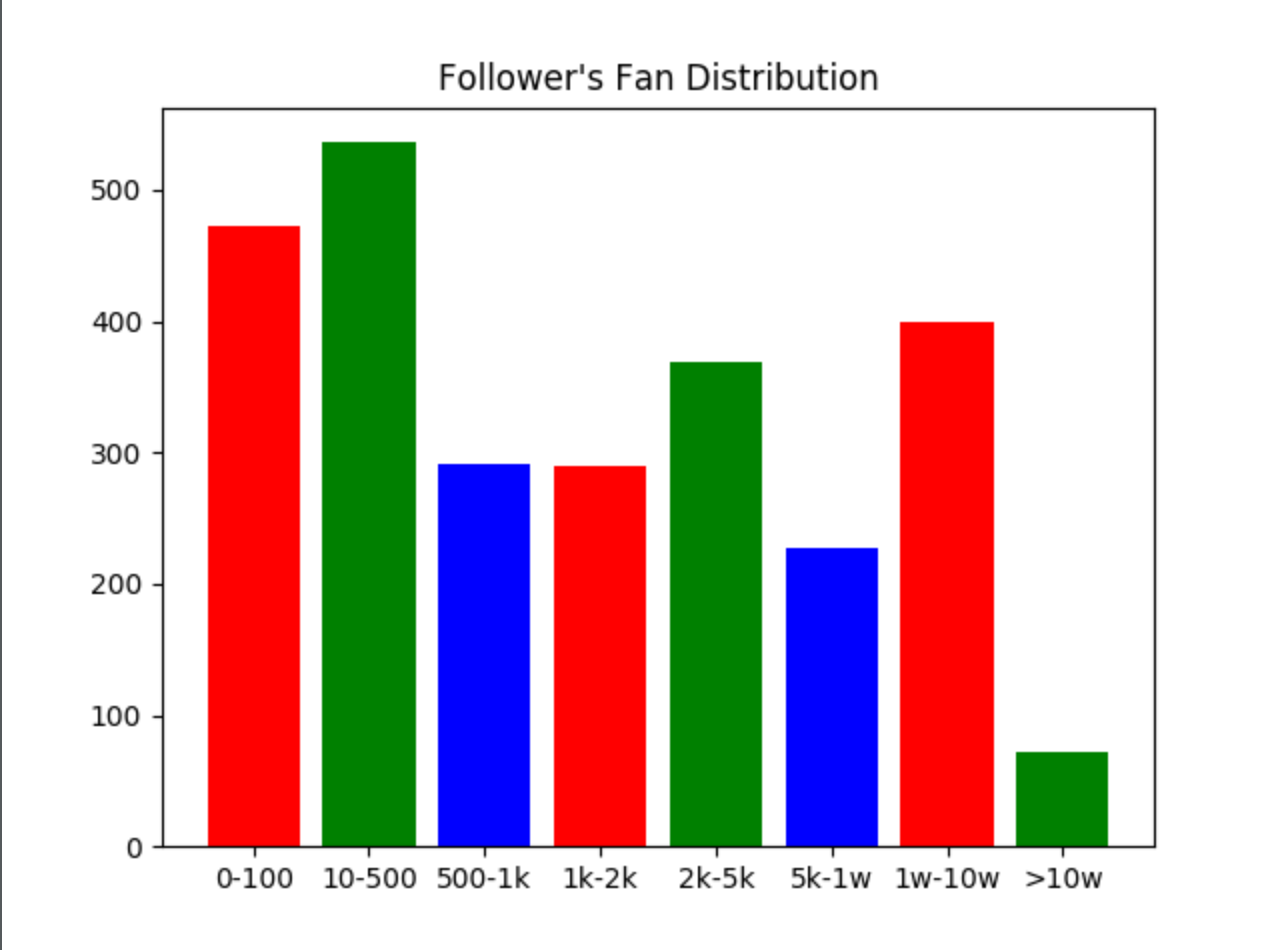
被轮子哥关注的用户中,这些用户的粉丝数量分布还是很均匀的,他们的粉丝数在 0-1k 范围内,占到轮子哥关注的用户的一半比例,轮子哥关注的大于十万粉的用户也有 72 位,其中轮子哥关注的用户中粉丝数最多是张佳玮老师,接近 160w 粉。
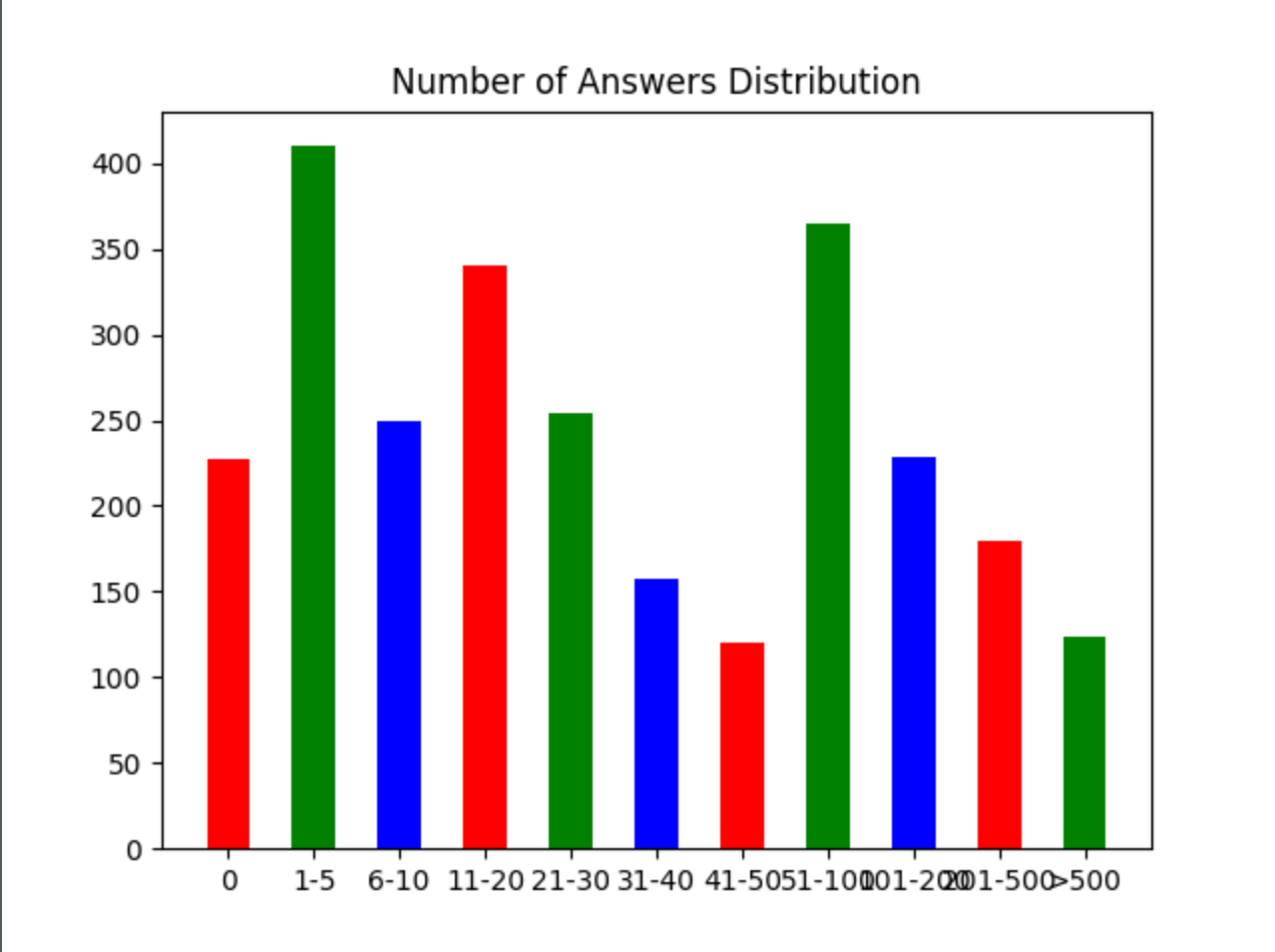
轮子哥关注的用户的回答数分布如上图,其中最高的三个柱子是回答了:1~5、51~100、11~20,其中 1~5 个回答数人数最多,有 410 个用户。其中,回答数 11~50 和回答数大于 51 的人数是差不多的, 这个是很有意思的情况。
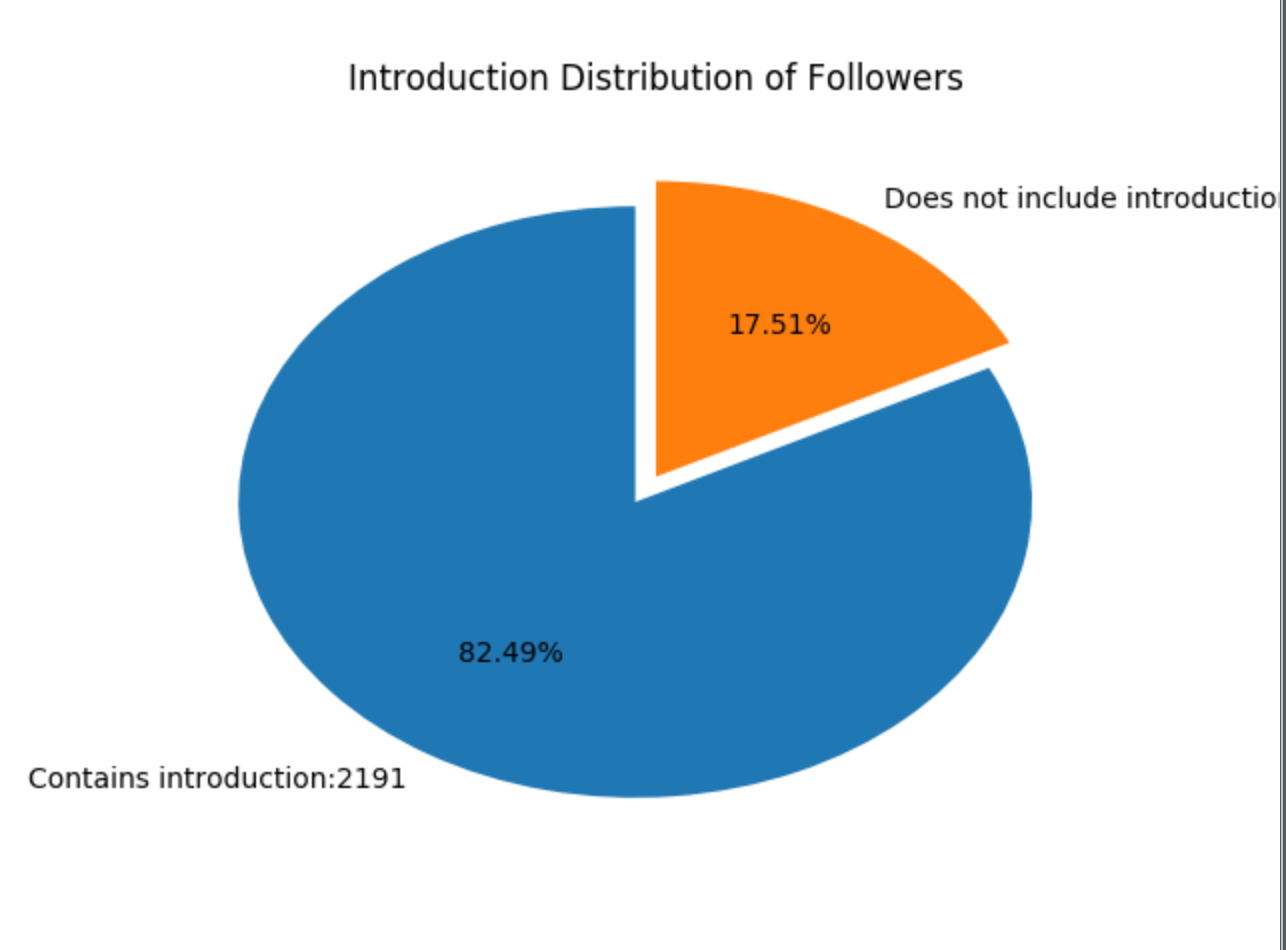
在轮子哥关注的用户中,有 82.49% 的用户个人信息中含有一句话介绍,17.51% 的用户是没有一句话介绍。
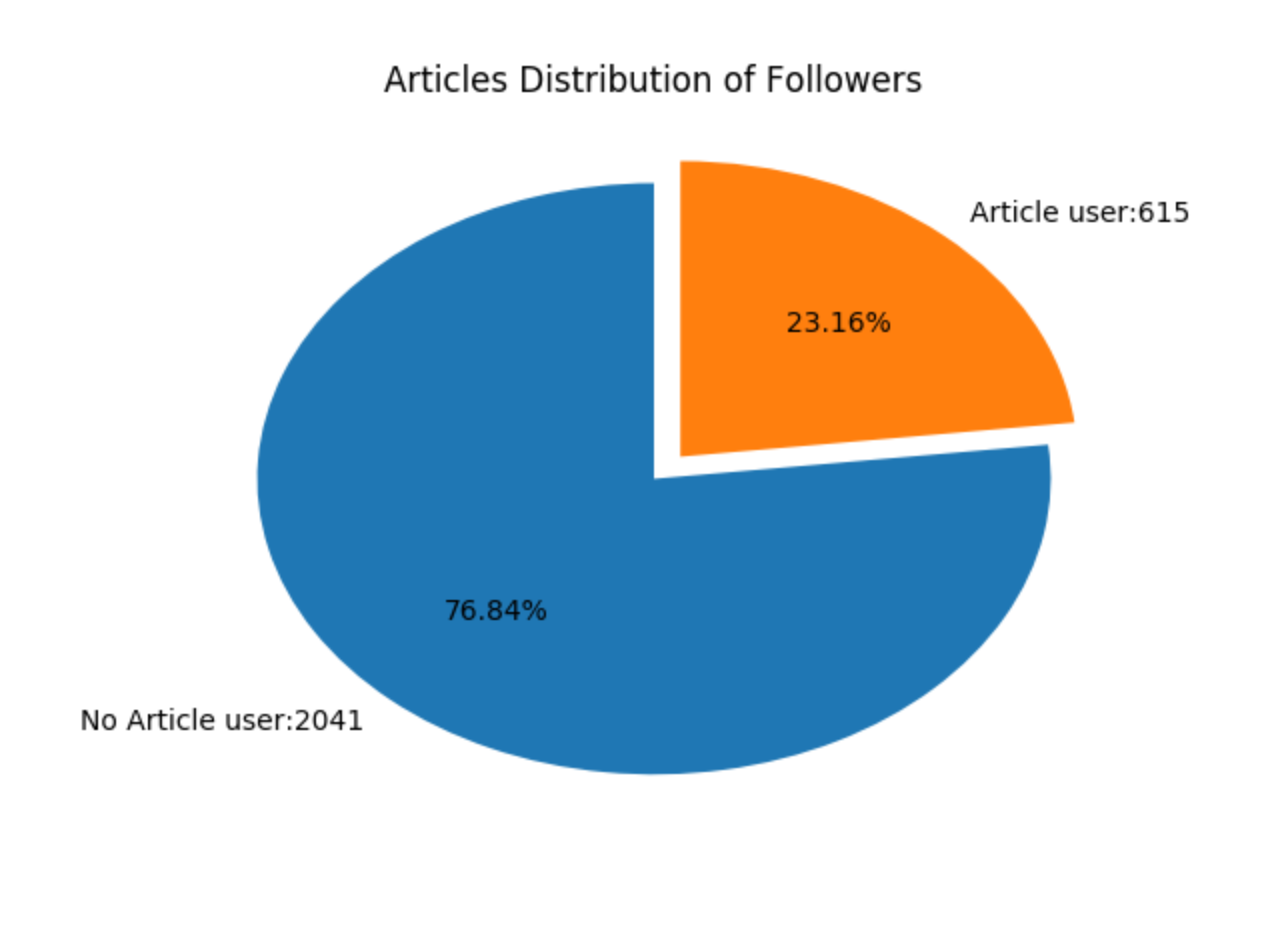
轮子哥关注的用户中,有接近 80% 的人是有文章输出的,而这个比例,接近之前含有一句话介绍的用户数量。